Making Machine Learning Fun And Accessible for Kids
Sarah T. VuAdventures in building a text training page suitable for kids with Cognimates.
 Sarah T. Vu and students from the Shady Hill School learning how to train a robot to recognize them with Cognimates
Sarah T. Vu and students from the Shady Hill School learning how to train a robot to recognize them with Cognimates
How it all started...
Hi, my name is Sarah, and while I normally prefer to write code, I am writing this blog post to tell you all about a project I’ve been working on for the majority of the past year. This project is called Cognimates, and it’s a platform for AI Education that originated from an MIT Media Lab project. Our original platform was used in our research workshops with kids age 7–14 all around the world (read more about our research). Through this experience, our team collected a lot of user feedback from children, and at the end of last year, we began to formulate a design to revamp the platform and grow it into a more sustainable, open-source project.
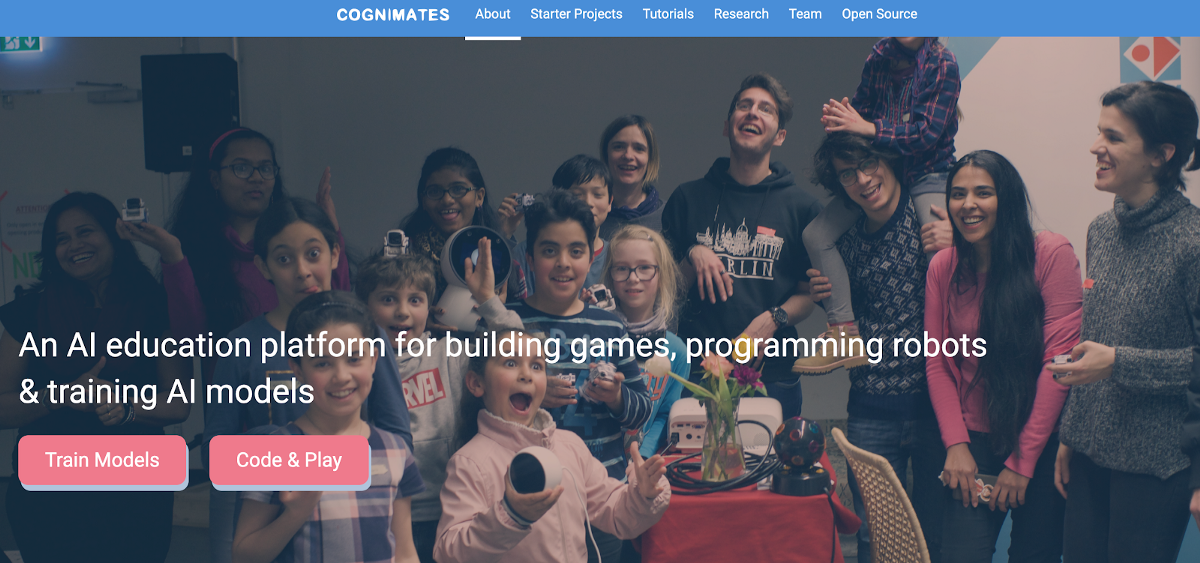 Website of the Cognimates Project (cognimates.me)
Website of the Cognimates Project (cognimates.me)
All of this happened while I was just starting my MIT adventure as a freshman. Despite my lack of experience in developing educational tools for kids, I was very interested in opening opportunities for young people of all backgrounds. I was also up for the challenge to learn full-stack development.
Hunting for the Right API
As part of my work on the Cognimates team, I took the challenge of implementing our text training from end to end. The goal was to allow children to train their own machine learning models with examples of text. The first thing I had to do was to find a reliable API to support our text training backend. Previously, we had been using IBM Watson which offered a limited free tier with only one free model. It was also slow, and their servers went down during several of our workshops, which was really getting in the way of kids having a good experience and learning. Our goal was to find APIs that have enough free options for kids, parents, and educator and which are backed by rigorous organizations. For our latest stack, we decided to use uClassify for text training, and I began to work on the implementation of this new setup. We later reach out to the uClassify team and they kindly agreed to also provide us with an academic free license to support our project.
A Quick Rundown of the Platform
Our platform has two main parts: a training studio, and a codelab.
The Training Studio
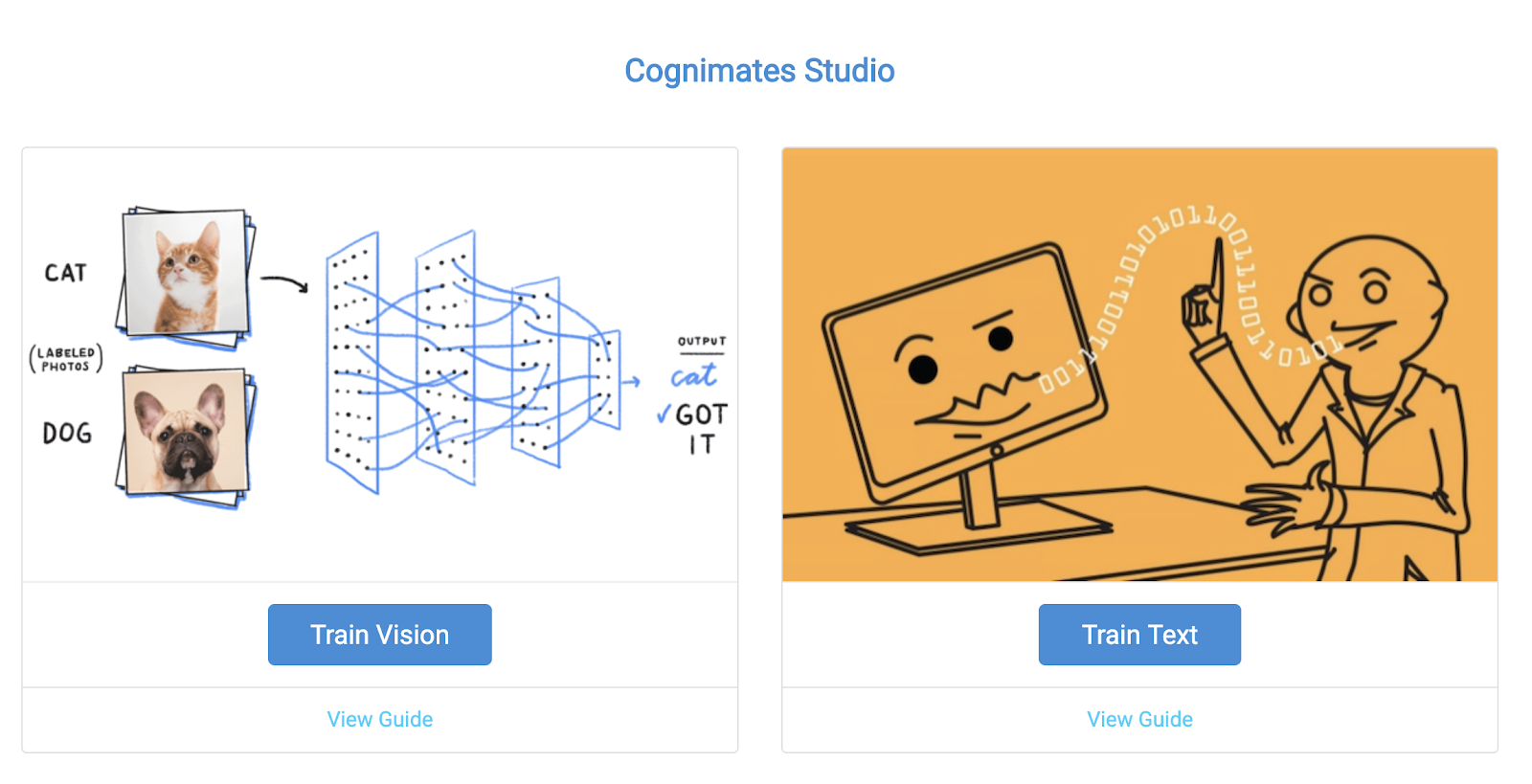 Home page of the Cognimates Training Studio
Home page of the Cognimates Training Studio
Our training studio currently has the option to create custom models with images and text. We also included guides to help our users learn how to get started.
Here are the first three steps for creating your own custom classifier with text: create a project, add your api keys, and enter the categories you would like to train.
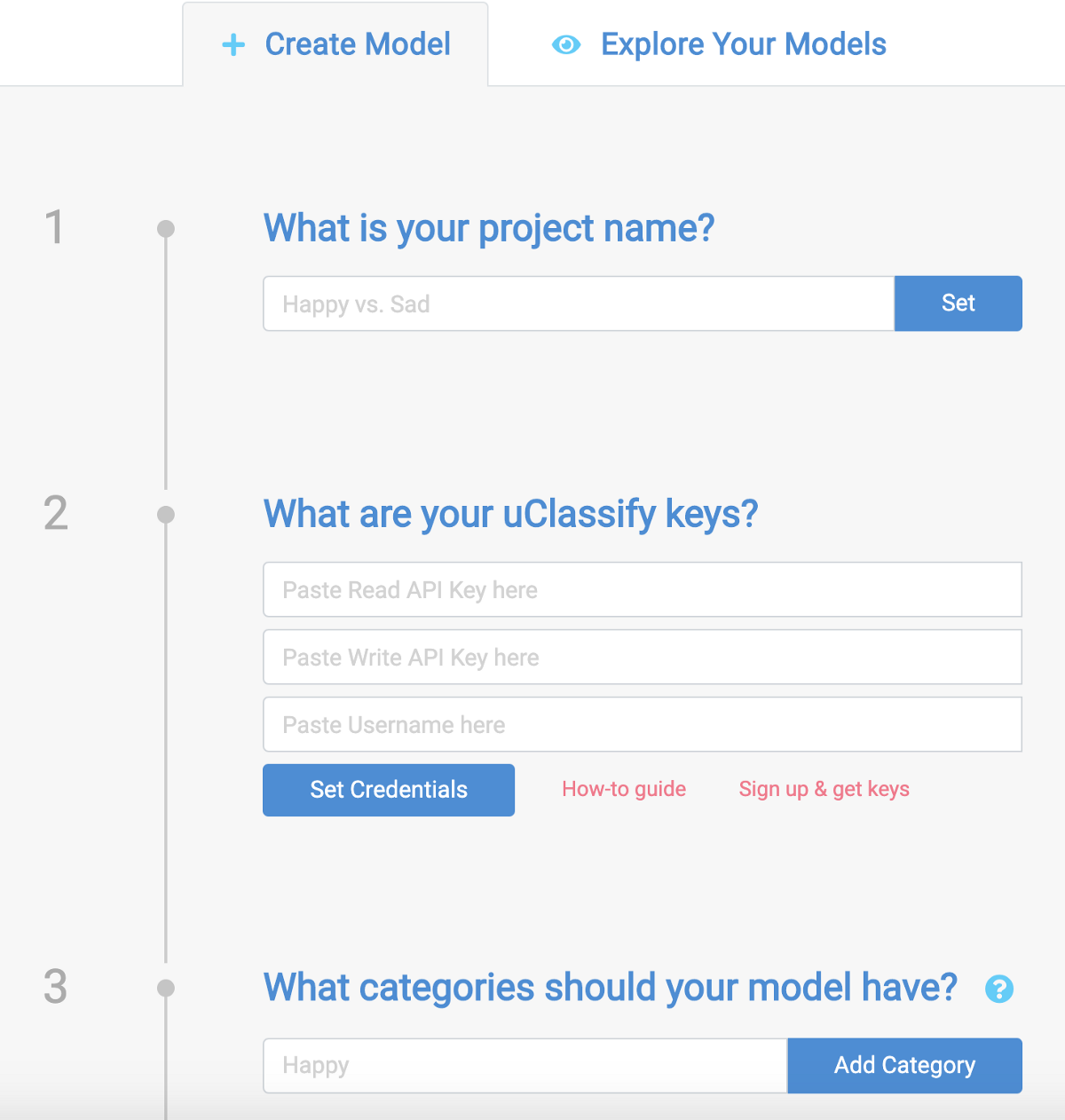 Example interface for creating your own text classifier
Example interface for creating your own text classifier
After creating a project, you can go to the explore tab and play around with your projects by testing predictions on different phrases. You may also choose to launch our codelab from the training page and use your classifier there. If you are curious and excited to try and remake this project yourself, I made a video tutorial to help you learn how to create your first machine learning classier with text in Cognimates step by step.
Video to help you create your own custom text classifier with Cognimates Text Training
The Codelab
The Cognimates Codelab allows you to use visual blocks to programs where you can control characters on the screen or physical components like robots or electronics boards. This platform builds on top of Scratch and is open source. Our codelab has several pre-trained machine learning extensions for sentiment analysis or speech recognition but it can also use custom machine learning models that users create in the training studio.
 Interface Cognimates Codelab (https://codelab.cognimates.me)
Interface Cognimates Codelab (https://codelab.cognimates.me)
Behind the Scenes
To take a look behind the scenes of the text training page, I’m going to use the “Recognize a Writer” demo project, created by William Mitchell, one of my colleague’s students at RISD ID in the “Designing Smart Toys” class.
 Example blocks from “Recognize a Writer” project
Example blocks from “Recognize a Writer” project
This project is using a custom text model trained to recognize the styles of Kerouac, Shakespeare, and Tolkien so when the user types any text fragment it would predict which writer was the author of that text. Writing samples for each writer can be added to train the model either from the blocks directly in the codelab or on the text training page by creating a new project and adding these training examples for each category.
Our interface for the training page was developed based on our experiences in the workshops we ran with children. We designed the interface to be simple and intuitive for new users. To train the “Recognize a writer” classifier, we first need to create a new project. Then, we will create categories for the different writers and add at least 10 examples of text to each of the categories so the classifier has enough data to train on.
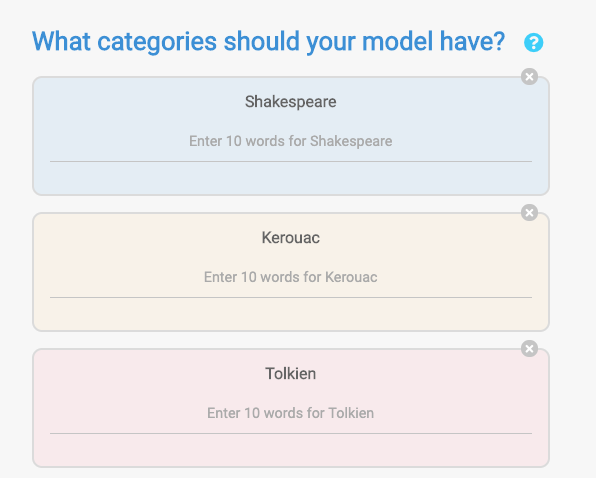 Examples of categories used to train a category in “Recognize a Writer” model
Examples of categories used to train a category in “Recognize a Writer” model
Once we finished adding the examples we can train and test the model. At this point, our text training page will send a request the uClassify API to use our project data and create a new classifier. The way calls are set up in this API is different from our platform flow. To preserve our flow and execute these different API calls efficiently for the data gathered from our platform, I ended up relying on async, which, was introduced to me by my teammate Eesh Likith. Using this method, I learned how to create a function that creates functions (see line 207) from the request body in JavaScript then performs those functions.
 Example of async function
Example of async function
From Training to Coding
After carefully crafting the ways we introduce the different steps and concepts on our training page, we began to tackle another challenge: transitioning seamlessly from our training platform to our codelab. While at the Media Lab, our founder Stefania Druga originally conceived the idea of creating Cognimates while being a student in the Lifelong Kindergarten Group which created Scratch. The Cognimates team has continued to work with the Scratch team and built our codelab on top of the Scratch stack before hacking the heck out of it with the goal of extending it for machine learning education. Today, we continue to hack the heck out of it.
Our latest hack was transitioning from the training pages to the code lab and copying over API keys and the project name. Before, users would have to copy and paste all of the same information used in training over to code lab in another tab, and this would get annoying. We wanted to see if we could make this step easier. We went in blind and guess and checked ways to correctly preload blocks into our code lab. What we ended up doing was passing in another script to our code lab that contained an “extension” (think of a Scratch object that specifies a set of related drag and drop blocks) with the blocks pre-filled with the user’s API keys and models from the training platform.
 Button on the training page that launches the Codelab
Button on the training page that launches the Codelab
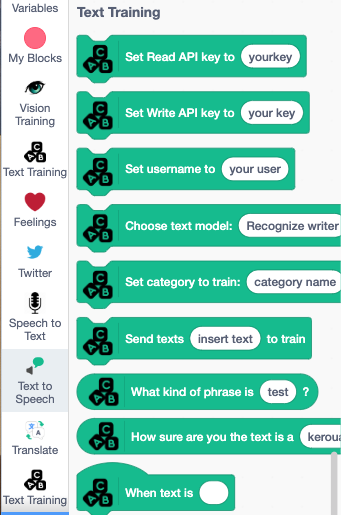 Examples of prefilled blocks that contain your custom data
Examples of prefilled blocks that contain your custom data
Designing With and For Kids
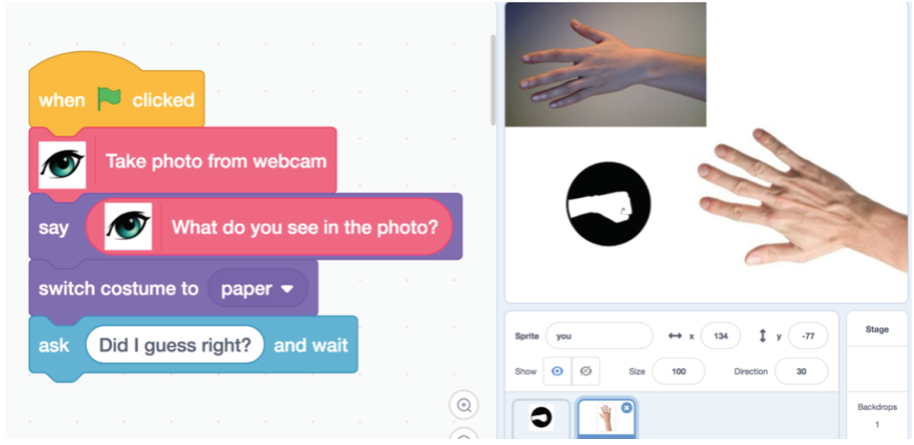
During the time I was doing my internship at the Media Lab conducting kids workshops with my teammates Tammy Qiu and Stefania Druga, we changed blocks’ wording very often. We were trying to figure out what language was most appropriate for children. The less technical our blocks’ language was, the better. For example, instead of using something like “label this picture” or “get the class of this picture” we used “what do you see in the photo?”. Examples of language we used for Vision blocksPersonally, I think a lot more thought goes into the way we word the blocks and our training platform than the actual coding. At least with coding, there’s usually a right answer somewhere on Stack Overflow. When trying to translate technical terms I see on a day to day basis into something ordinary people and children can understand, there’s not really a right answer, but there’s a best answer. I see it as me freaking out over Microsoft acquiring GitHub, then having my non-technical friends and parents ask “What is GitHub?”. Well, Mom, it’s kind of something I have to live and breathe with every day.
Keeping it weird
After the technical work, we get to have some fun with our team. My favorite Cognimates characters (check out the characters we have added to the sprite library) are Major Tom and Minor Tom, and that’s only partially because I got to name them. Major Tom is the larger space panda, and I was inspired by one of my favorite songs, Space Oddity. Minor Tom happens to be smaller, hence the minor in his name. They are also both very, very cute.
 Examples of Cognimates characters designed by Mircea Dragoi: Major Tom and Minor Tom
Examples of Cognimates characters designed by Mircea Dragoi: Major Tom and Minor Tom
A Look in the Rearview Mirror….
With our small team and a task list that grows faster than we can finish it, I’ve had the opportunity to grow and push myself in every way possible. I started this project knowing nothing about JavaScript and Node.js, and with each new challenge, I get to learn something new (like async!). I am also very grateful for the challenge and the opportunity to learn how to think about my work and my interests in terms of something everyone can understand. It’s a step all developers should take to make their work more accessible, especially in explaining how machine learning works. While the education system tries to catch up on its offerings of tech (and AI) literacy, the best the tech industry can do is to find better ways to communicate and make transparent this big “black box” that machine learning is to the general public. It would support better regulations and critical use for machine learning algorithms used in the lives of everyone. At the very least, it will contribute to a more informed Twitter debate when Alexandria Ocasio Cortez brings up racism in machine learning algorithms. With our work, we aim to make a small dent and allow children and their parents to also learn how machine learning works by creating their own custom classifiers and using them in playful ways.
….. And the Road Ahead
This project has been a large part of my life in the past year, and I hope to see people from all walks of life learning playfully and creatively with our platform. In the past, we’ve had both graduate students prototyping designs with Cognimates and kids as young as seven using it to predict whether a picture contained Kirby, a dog, or sunglasses. On the other side of this project, we’ve also had tremendous support from the Scratch team, uClassify, Clarifai, the Superrr Network and Mozilla, MIT Sandbox, educators, and developers who have helped us prototype, test, and translate our work. This community continues to grow, and I hope that you, the reader, will join us on this journey as we try to create a future where playful learning with difficult concepts becomes a standard rather than the exception.
 Cognimates team (Left to right): Tammy Qiu, Stefania Druga, Sarah Vu, Eesh Likith. Not pictured: Steven Dale
Cognimates team (Left to right): Tammy Qiu, Stefania Druga, Sarah Vu, Eesh Likith. Not pictured: Steven Dale